Magi-1:自回归扩散模型
落花流水。
最近一年都关注着Diffusion领域,与大红大紫的DiT-based视觉生成模型的不同,扩散语言模型(Diffusion Language Models,DLMs)颇有隐而不发之意,虽反响不甚热烈,又偶有令人惊艳的工作出现。对研究者而言,这是一片蓝海,押宝于这个方向不失为一种优良选择。
昨天还在想怎样才能把视频生成模型做成自回归的,今天就看见了这个重磅模型的发布。Vidu Q1也在同期宣布登顶VBench,但是得到的关注度注定远不如MAGI,因为这是首个开源的自回归式视频生成模型,在这个双向扩散视频生成已经卷上天的时代,一个全新架构的开源已经足以令人兴奋,更何况其效果不输SOTA!
更重要的一点在于,视频是我认为最应该自回归的模态。
所谓的“流式媒体”,如视频、音乐,天然具备时间维度——一支单向前进的箭矢。人类观看一段视频,永远只能一帧一帧从头到尾看,而不可能毫无因果地共同处理多帧的内容。但现有的双向扩散视频生成模型,则完全忽略了因果性,只能将所有帧共同计算,同时输出,这是不符合流式媒体的特征的。更何况,这种全向注意力的扩散模型范式锁死了生成的扩展性,不考虑生成质量,目前的开源模型最长也就15s,无论从算法侧还是算力侧考虑,更长时间的视频生成都有巨大困难。人脑具备根据前几帧脑补后续视频的强大渲染能力,而现有全向模型完全不行。因此,我的暴论是,全向扩散的视频生成模型是不美的,是不自然的,再怎么卷也不会是最优解。每次出来一个所谓的SOTA视频生成模型,我都点开看看,然后叹口气。
但这一次点开,我倒吸一口凉气!我一直期待的是MAGI-1这样的作品!终于有人成为了我暴论的有力支撑!因此我第一时间读了他们的技术报告,不得不说Sand-AI的工作很solid啊,里面有不少精华,感觉都够发两篇了。我也趁热打铁提要一下里面比较有趣的地方,与大家共同学习。
出于个人专业原因,下面提及的点主要从infra视角出发,算法、数学什么的我搞不明白就不卖弄了。
模型架构
看模型架构,和全向的模型相比,有什么不同吗?起的名字虽然花里胡哨,其实没有大不同,仍然是DiT Block堆叠组成DiT(左),DiT内部由Attention+FFN组成。右下的Parallel Attention Block也是比较常规的架构,由于Text Cond的embedding后其实很小,整个模型的主要开销仍然在Block-Causal Attention,同样,算法最核心的不同也在这个“Causal“上。
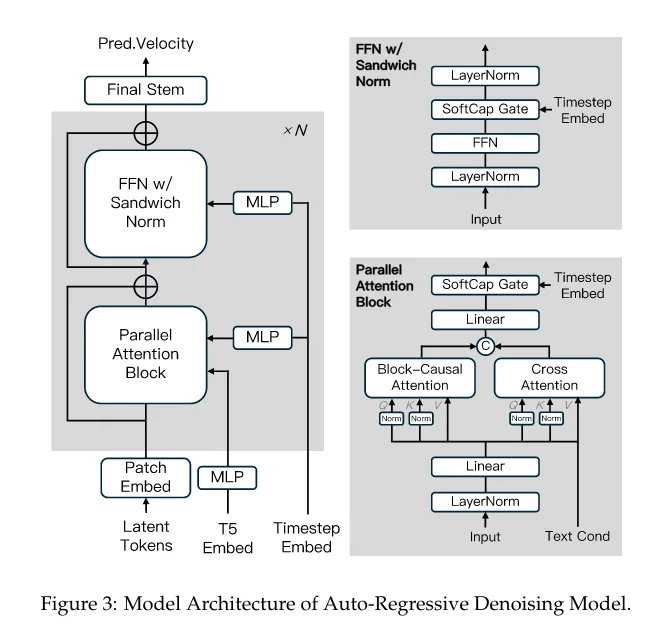
Block-Causal Attention
经评论区补充,对于Block-Causal Attention,此事在CausalVid (CVPR2025)中已有记载。
这里的Causal Attention和LLM中的自回归attention也是不同的。对于文本,只有一个序列维度,自回归生成是token-wise的。但对于视频,其实有时间和空间两个序列维度,我们只能在时间序列维度做自回归,也就是说,最细也就是一帧,但一帧仍然由多个token组成,仍然需要全向的扩散attention做。因此MAGI的Causal Attention是Block-wise的,此处设置了1个Block为24帧。基本的Block-Causal Attention Mask如下图(e)所示,apply了这个mask的attention,每个block只会与自己之前的blocks计算attention,未来的block则无需事先知道。
从算法侧看,由于视频帧之间本身相似度就很高,以帧为粒度,从双向的注意力改为单向注意力并不是很难的事情,CausalVid中通过从双向模型蒸馏和微调完成。但是,要多快好省地完成这件事又是另一回事了——Block-Causal Attention是一种全新的attention模式。这带来了系统实现的挑战。
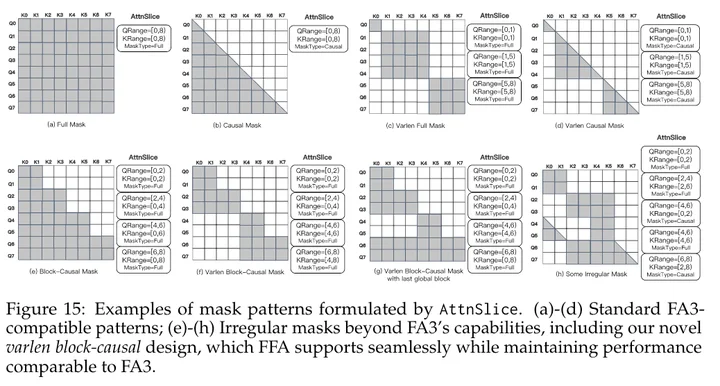
Flash-Attention是只支持Full Mask和Causal Mask两种形式的,如上图的上半部分所示,一般来讲,diffusion中attention用a和c模式,LLM中attention用b和d模式也就够用了。现在整个Block Causal Mask,类似于在causal mask中粗粒度地融入了full mask,这只能由Sand-AI自己实现。很给力,Sand-AI实现了Flex-Flash-Attention(FFA),高效支持了各种不规则的mask。
自回归式前向计算
有了Block-Causal Attention,我们可以简单地实现自回归式的前向计算,即逐个block先后输出,而不是所有帧需要被同时计算出来。具体的算法如下图,但这个图画的有点简陋,看了很久才勉强理解。
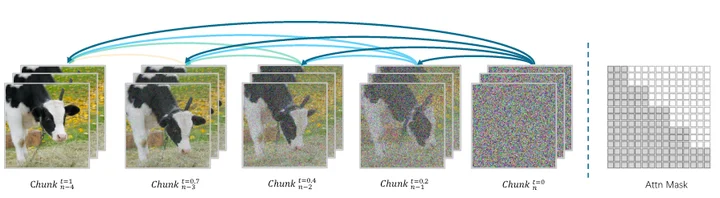
这里引入了timestep这个新的维度,其核心应该是想表达一个chunk-wise的流水线去噪过程(注意这不是流水线并行,而是在一张gpu上实现的不同时间步的多chunk推理),在chunk n-4(左1) 已经完成计算的同时,chunk n刚刚开始计算(右1),chunk n需要依赖前4个chunk的kv,对应最下一行Attn mask,而chunk n-4的推理则只依赖于自身。这一个流式计算的pattern,将为视频生成的算法侧和系统侧优化,带来无限的可能,首先就是KV Cache。
KV Cache!
是的,我们视频生成也有KV Cache了。先前生成的block的KV,在后续的block attention过程中仍然需要被使用,为了保证计算的高效,KV Cache是自然且必要的。内存限制不能每一步的KV都存,因此设置了5步存一次,引入部分的重算。回来了,都回来了,自回归+KV Cache,我已经可以预见到一系列vLLM4Video、MoonCake4Video之流的赛跑灌水文的诞生了。
分布式训练
MAGI-1作为自回归模型+去噪模型的结合,其实是一种全新的负载,可谓集百家之短。其分布式训练使用了数据并行(DP),序列并行(CP)和张量并行(TP)。DP切batch维度,CP切sequence维度,TP则切模型,在MAGI-1的训练上,各有各的挑战。
DP:训练中使用的视频长度是不同的,对于同一个batch中的不同序列长度样本,Sand-AI提出了Distributed Packing and Padding(PnP)的训练策略,并因此设计了Flex Flash Attention机制。
CP:Flex Flash Attention在单GPU上被实现了,用来支持不规则的attention mask,那在序列并行情况下要怎么实现呢?又是一大挑战。
Distributed Packing and Padding
PnP的思路很简单,训练过程中的序列长度是固定的,但输入数据的序列可能更短,因此会做padding,在冗余部分补零,这就浪费了计算资源,于是往冗余部分填入别的短数据。对于离线的训练数据情况,这是非常经典的bin-packing问题:固定的bin-size和变长数据,找出最小冗余的打包策略。这是一个NP完全问题,但已经有不错的近似算法。MAGI-1的情况则是加入了3D并行和流式输入的更复杂的bin-packing问题:对于M个候选样本,将它们装入N个max_length的bin(batch)中,此处的N远小于M,且N要被DP size整除,max_length则要被TPxCP size整除,它们都是可调的超参数!
MagiAttention【重磅】
Block-Causal Attention + PnP策略引入了复杂的attention mask,因此Sand-AI提出了MagiAttention,来高效解决长序列+复杂mask的attention计算问题。
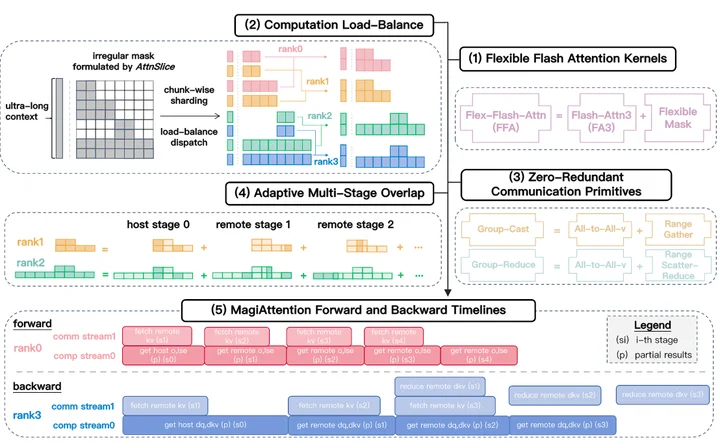
我们来尝试理解一下。
- Flexible Flash Attention算子:在单卡上支持复杂mask的Flash Attention3算子实现。
- 计算负载均衡。经过pack and padding后的batch,其attention mask是复杂且巨大的,序列并行仍然是必要的,因此需要合适的序列切分策略,实现序列并行的负载均衡。
- 零冗余通信原语。复杂的序列切分和因果的attention mask使得原生的序列并行(Ulysses,Ring-Attention)通信注定是次优的,因此需要重新设计通信原语实现高效的block-wise通信。
- 自适应多阶段重叠。这里说的应该是序列并行的计算通信重叠。Ring-Attention中有非常naive的P2P计算通信重叠实现,因为这里的序列形状太诡异了,MagiAttention对自己的通信原语提供了自适应或自定义的计算通信粒度调整策略。
- 整体的MagiAttention Pipeline。这个图也有点难理解,大概是想表达通信开销最大程度地被计算掩盖了吧。
说着简单,每个其实都是巨大的工程量和细节,具体的设计技术报告中也提供了,不多赘述。
这里就不得不佩服Sand-AI深厚的AI Infra底蕴了,为了实现一个简单的自回归的diffusion算法,自己写了一整套专用的计算和通信算子,并设计了完整的系统来实现线性的可扩展性。我开始怀疑,自回归diffusion迟迟不出现,是不是infra问题,而不是算法问题😂。
分布式推理
自回归式视频生成最美妙之处,就在于流式推理和人类肉眼观看的因果性的完美适配:24帧每秒,就是流式推理量变到质变的瞬间。因为更快的推理速度对在线视频服务没有太大意义了,就像4G和5G在看视频体验上没有太大区别一样。不知道是好消息还是坏消息,Sand-AI宣称在H卡上已经达到了这个实时流式推理的标准,它们还很贴心地提供了支持4090部署的模型。好,那么好,往上往下都让他做完了,哈基沙你真的……
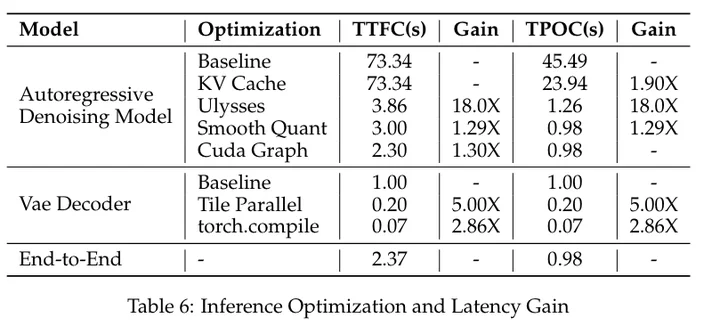
首先是两个熟悉又陌生的指标:TTFC:第一个block生成出来的时间;TPOC:后续block之间生成的时间。
然后是几个推理侧的挑战。
- Diffusion模型包含多个异构组件:T5 encoder用于处理文本prompt,VAE用于编码和解码图像和视频,DiT用于去噪。T5和VAE是访存bound的,DiT是计算bound的。
- 对于24帧每个block的设置,TPOC小于等于1s就可以宣布实现了实时生成,这需要9PFLOPS的算力,因此需要高可扩展性的分布式推理达成这个目标。
- 第一个block的推理与后续block的推理不同,它不是计算bound而是cpu bound!应该原因就是卡太多了,但是要算的太少了,没打过这么富裕的仗。
让我们看看,在3机24 H100集群上,Sand-AI如何高效跑出24B的MAGI-1。
异构服务架构
T5和MAGI-1共同部署在GPU上,而VAE部署在cost-effective hardware(我猜是CPU,还有啥硬件)上。在流式推理中,VAE和DiT的流水线式分离几乎是必然的,这样可以保证二者的同时运作,中规中矩。
TPOC优化
- 量化。使用了W8A8量化,带来30%加速。Hopper架构的FP8量化,中规中矩。
- 多机并行。基于Ulysses的序列并行推理,加充分的计算通信重叠,wtf跨机情况下只有3%的未隐藏通信开销?!看上面的Table6,24卡的ulysses带来了16倍的加速比,很神奇了。附录2中提供了具体的推理细节如下:Ulysses在q,k,v和o上面做4次all2all计算。v通信和k计算重叠,k通信和q计算重叠,q通信和KV cache的计算重叠,o通信和cross attention的计算重叠。我汗流浃背了Ulysses原来可以这么玩……
TTFC优化
各种优化技术往上堆,中规中矩。
4090推理
主要需要考虑4090的24GB内存墙的限制,慢点不是问题。对于单卡,用了4.5B的蒸馏模型,W8A8的量化,KV Cache offload到CPU上,中规中矩。对于8卡,仍然是内存墙的问题,用了序列并行+流水线并行的混合并行。4090用pcie做卡间通信,ulysses通信没法重叠了,于是提出了context shuffle overlap方法。
效果
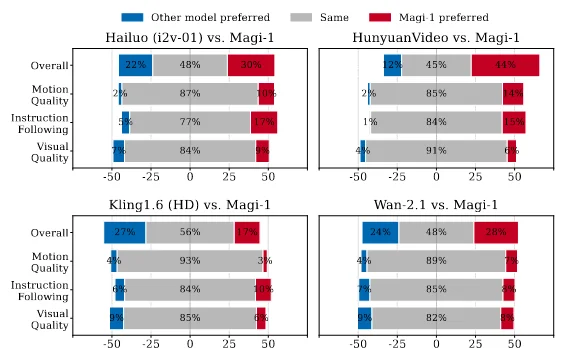
看中文三大顶刊上的实测,貌似效果中规中矩吧,其实对视频效果的量化评测一直都没个准数,VBench上的所谓登顶也是许久不更新一次的I2V赛道。说实话,我觉得这个模型在架构和infra上的意义已经很高了,没有必要再强求精度去和别人卷。
过几天看别人的实测,原来生成效果甚至不如中规中矩,没法和混元万象去比。对于同一个算法,这种块状自回归注意力的效果是必然不如双向注意力的(少了整整一半的信息),但我还是认为,不应该否定这种自回归思路的潜力。说什么这个公司拿半成品出来圈钱的人有点消极了,自回归逐帧生成的路线应该是对的,就看算法能怎样在此基础上扩展了。
我是一边读一边写的这篇,通篇读来着实有点意外。
没想到啊没想到,一篇tech report,大半篇在介绍infra的实现。本来想着找点机会,人家直接把解决方案端上来了。这是否在宣告着一个趋势,infra友好已经成为算法设计的门槛了。算法两下就讲完了,我只是想在diffusion model上apply一下block-casual attention mask而已——嘿,您猜怎么着,为了省点钱和时间,我得设计专用的计算和通信算子,专用的分布式训练和推理系统。这个过程太深刻以至于他们在4.1.3节专门写了“Rethinking System Design for Robust Distributed Training Frameworks with DTensor”,批评现在的分布式系统和算法耦合太严重,稍微更新一下算法就得写一整个新架构。以前都是架构跟着算法走,现在算法也得看架构的脸色了(乐)。