视频生成模型能成为世界模型基座吗
效率是直接矛盾,但不是根本矛盾。
生成式AI的格局相比一年前我入坑的时候已经大不相同:DiT的架构趋于收敛;NanoBanana、Seedance等闭源模型也实现了极好的生成效果;开源模型不再军备竞赛式更新。但是问题仍然存在:AIGC应该如何变现?如何在实际生产中产生革命性的作用?就像LLM发展为Agent一样,通过提供工具调用能力,掀起一波token消费的浪潮。目前在aigc中,我们没有看见这一点反而是Sora2停摆,Seedance2降速,无不反映着视频生成面临的尴尬处境:很fancy,但没用。
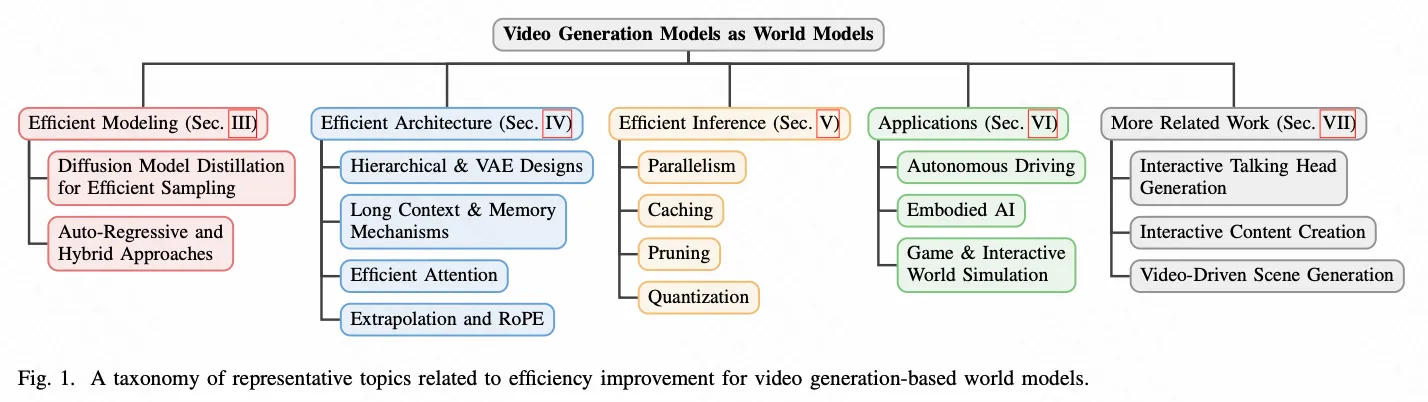
那么视频生成模型(VGM)的Agent形态是什么呢?也许是世界模型(WM)?我最近阅读到一篇综述:Video Generation Models as World Models: Efficient Paradigms, Architectures and Algorithms,来自香港大学。
为什么说视频模型拥有作为“世界模拟器”的能力?
世界模型的定义:一种环境动态的表征模型,可以通过历史的上下文+当前行为(actions)预测未来的状态。对于视频生成模型来说,生成过程就是对物理世界的模拟过程——它需要考虑到自然环境的重力、碰撞和各种因果关系才能够生成足够“真实”的视频。
因此,视频生成中常用的video frames + prompt的生成方式,也是世界模型中历史上下文+行为的一种输入模式。考虑到现在的模型生成质量足够优秀,我们可以大胆猜测:经过大量视频片段的训练,模型习得了真实世界中足够的物理常识和经验。
综述中说,视频模型作为world simulator有这些好处:
- 物理智能:经过大规模训练的模型能够学习到传统分析所无法驾驭的复杂的交互作用,例如智能体与环境的交互或流体动力学。
- 潜空间分析:视频模型通常在压缩过的潜空间(Latents)中运行,这使得世界模拟能够以比高分辨率像素渲染更低的计算成本实现。
- 统一推理:通过将视频生成视为世界模型,相同的架构可以应用于从媒体制作到自动驾驶和机器人操作等各种领域,在这些领域中,模型充当通用的决策模拟器。
这些并不算是非常promising的好处,只是我们暂时没有更好的替代罢了。
限制VGM作为高效的世界模拟器的,主要是效率问题。可用的世界模型要求实时的响应速度(具身、智能驾驶),这是当前VGM所不具备的,扩散的迭代去噪模式导致的高计算和高延迟,自回归模式则引入巨大KV Cache开销,无不阻碍着VGM向实用WM转化。
这篇综述关注就是如何从算法、架构、推理优化的角度去提升VGM的效率,同时给出VGM向WM转化的应用和相关工作。
背景:关于视频生成模型(VGM)
对于不了解VGM的读者,我尝试简洁地描述本文关注的workload,进行一次阅读所必须的background同步。
视频生成模型的 workload 特征如下:视频经过时空 tokenize 得到 latent 序列,与条件信息一起送入 DiT(Diffusion Transformer)。DiT 是核心 backbone,其计算瓶颈在 full attention,全过程计算密集,长序列时 self-attention 占总计算时间 80% 以上。生成(Inference)是迭代去噪过程,每一步 DiT 输出经采样后需重新送入模型,所有 token 均被更新,因此无法像 LLM 解码阶段那样利用 KV cache 加速。
如果你了解llm,那么视频生成过程从负载上等同于一个长序列的多次prefill过程,你也就能理解为什么它那么慢。
VGM为什么慢
从系统负载的角度看,视频生成模型慢的原因其实很清楚:它可能是我见过冗余信息最多的一类模型。多到令人发指,追求计算和架构美感的人绝对无法接受“这就是DiT的终点”的陈述。
你能够想象一个5s 720p的视频,最终压缩成mp4可能不到1MB,需要接近1GB的tokens与30GB的模型权重计算50次,耗时接近3000秒吗?
它的基本路线是“以量保质”:更多数据、更大模型、更高分辨率、更长序列、更多denoising step、更密的attention连接,最后憋出一个还不错的答案。这个路线在生成质量上是成功的,但在计算效率上非常奢侈。
我倾向于把其中的冗余分成三类。
数据冗余
与文本的高信息熵不同,图像和视频有大量相似像素。相邻像素相似,相邻帧相似,背景区域相似,很多局部纹理也不需要逐点建模。视频天然适合被高度压缩。
VAE、latent compression、hierarchical generation、pyramidal generation这些方法的存在,本身就说明了数据冗余是真实存在的。现代视频生成不会直接在像素空间里做扩散,而是先把视频压成latent,再在更小的表示空间里建模。
算法冗余
DDIM和flow matching都通过多步迭代去噪的方式求近似解,本质上也是一种堆算力的过程。每一步都把完整latent序列送进DiT,更新所有token,再进入下一步。它不像LLM decode那样只生成一个新token,而更像是在做很多次长序列prefill。
算法冗余最直接的表现,是相邻denoising step之间的中间特征高度相似。蒸馏和cache之所以能工作,就是因为这个冗余真实存在:前者尝试少走几步,后者尝试少算一些。
架构冗余
DiT中的full attention引入了大量不必要的连接。视频token之间当然有全局关系,但不是每个token都需要和所有token做同等精度的交互。训练后的模型本质上是稀疏和可量化的,SageAttention和大量sparse attention工作都说明了这一点,详见我的另一篇文章《稀疏注意力》。
Sparse attention、window attention、linear attention、SSM、pruning、quantization这些方法带来的巨大加速,都是在不同层面证明并利用架构冗余。Full attention和全精度计算只是当前“以量保质”路线下最稳妥也最昂贵的默认选择。
加速VGM
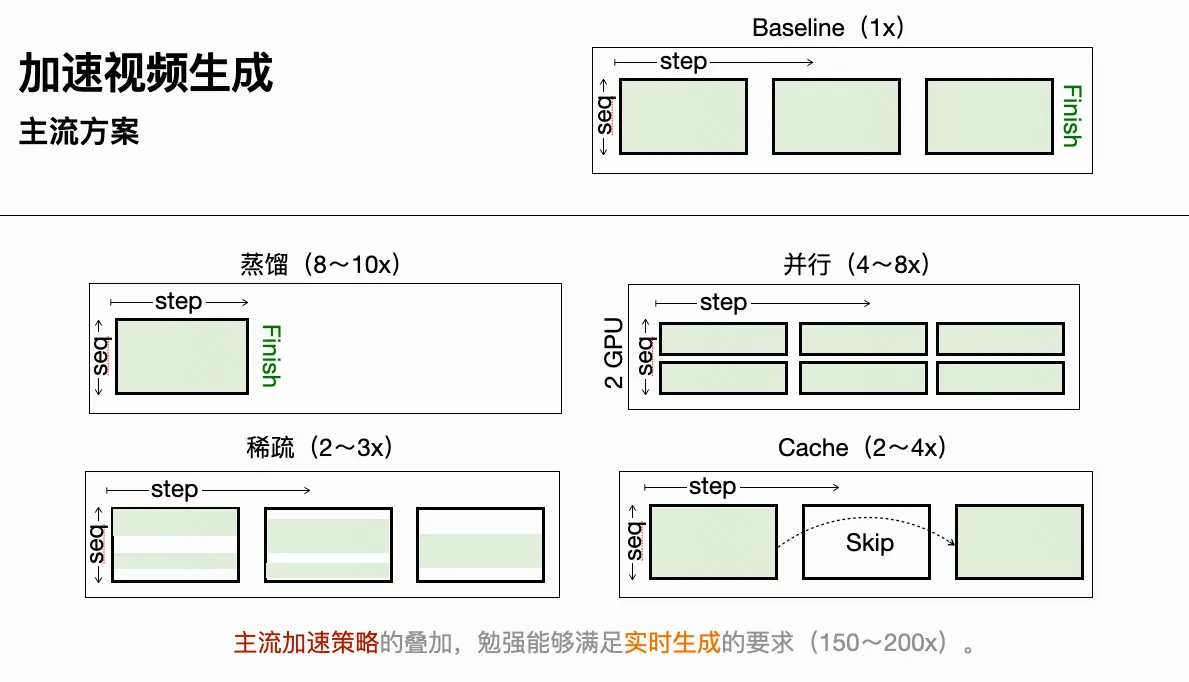
按照上面的冗余来源,VGM的加速方法可以总结如下:
压缩数据
VAE、latent compression、hierarchical generation、pyramidal generation,本质上都是减少模型需要处理的状态规模。先把视频压到更小的latent,再把生成过程拆成粗到细的阶段。这类方法利用的是视频自身的数据冗余。
这条线很重要,因为它决定了后面所有计算的基数。如果token数量本身降不下来,后面的attention、cache、parallelism都是在一个巨大的负载上做补救。
现在主流架构是VAE加DiT:VAE负责把视频变成latent,DiT负责在latent空间里建模分布。这个分工在工程上很自然,但我觉得对世界模型并不可靠。
原因是VAE优化的目标通常是重建质量、感知质量和压缩率,而不是“世界状态的充分统计量”。它可能保留了足够生成好看视频的信息,却未必保留了用于交互和推理的关键信息。VAE把复杂世界压成latent时,并不知道未来哪些信息会被动作、规划和长期一致性用到。它压掉的可能正是后面需要推理的东西。
真正的压缩不应该只是视觉压缩,而应该是面向状态的压缩:哪些变量需要长期保留,哪些关系需要可查询,哪些物体需要在遮挡后仍然存在。这不是单靠一个重建式VAE能保证的。对普通视频生成来说,局部瑕疵也许可以接受;但对世界模型来说,压缩如果丢掉了几何关系、物体身份、空间拓扑,后续决策就没有意义。
减少步数
蒸馏是目前最有效的采样加速路线。综述里提到的GPD把Wan的采样步数从48步压到6步,VideoLCM、AnimateLCM、TurboDiffusion等方法进一步推动few-step和one-step视频生成。
这类方法的价值非常直接:扩散推理成本近似和step数线性相关,少一步就是少一次完整DiT计算。因此在真实部署里,蒸馏往往比很多花哨的attention改造更有用。
但它解决的是短视频生成效率,不解决长时序世界模拟。你可以更快地生成一个clip,但不代表它能稳定rollout一分钟。
复用计算
Cache利用的是算法冗余。相邻denoising step之间变化有限,很多中间结果没有必要从头算。PAB、TeaCache、FasterCache、PreciseCache是通用视频生成里的代表,WorldCache则更明确地面向world model,试图识别哪些token变化剧烈、哪些token可以跳过或预测。
Cache的优点是工程上比较直接,不需要完全改模型结构;缺点是和蒸馏存在一定替代关系。模型步数越少,cache空间越小。而且对world model来说,错误不是均匀分布的,关键动态区域的一点近似误差可能会在后续rollout里放大。在不缺数据而缺服务算力的工业级生产环境中,cache几乎是首先被排除的选项:如果cache还有效,不妨再蒸馏一下。
稀疏和量化
Full attention太贵,权重和激活也不是每一位都同等重要。Sparse attention、window attention、linear attention、SSM、attention quantization、PTQ/QAT都在利用架构中的冗余性。
Window attention利用局部性,sparse attention选择重要token或block,linear attention和SSM试图从复杂度上绕开$O(N^2)$。Pruning和token merging则试图合并或删除不重要的token、层、head或channel。
改架构的另一个问题在于infra,比如:稀疏是否真的转化为wall-clock speedup。稀疏策略本身不难想,难的是同时满足三件事:选择准确、硬件友好、额外开销小。很多工作的问题不是没有减少FLOPs,而是减少的FLOPs没有变成真实加速。稀疏如果不硬件友好,最后可能只是在论文里省了FLOPs,实际运行却被不连续访存、top-k选择和kernel launch开销吃掉。
Pruning和token merging还面临另一个问题:视频生成的问题不只是“现在有多少token冗余”,而是“哪些token在未来会变得重要”。一个当前看似不重要的背景物体,几秒后可能成为交互对象。短视频指标上能省,长时序rollout里可能就开始还债。
量化则更像部署标配。SageAttention系列说明attention可以被推到很低精度,FP8/INT4/FP4都会越来越常见。但量化解决的是单步计算和显存成本,不解决算法层面的长时序一致性。
并行执行
Parallelism不是消灭冗余,而是把冗余摊开。它的优点在于,这是屈指可数的无损加速方法:只要堆资源,原则上不需要牺牲生成质量。相比蒸馏、cache、稀疏、量化这些近似方法,并行至少不改变模型本身的计算语义。
空间维度、时间维度、sequence维度、pipeline维度都可以拆到多卡上执行。对于DiT这类模型,sequence parallelism和patch parallelism都比较自然。它的意义在于让大模型跑起来,尤其是高分辨率和长视频场景。
但如果只看单样本生成,不考虑data parallelism,并行的可扩展性并不高。DiT不像LLM decode那样有明显的prefill/decode阶段差异,也没有KV cache带来的访存主导阶段;它的全过程都偏计算密集,基本就是一次又一次把大矩阵乘和attention铺满。因此并行方法的创新空间并不大,更多是工程上的切分、通信隐藏和负载均衡。
所以并行通常解决吞吐和显存,不一定解决单用户实时交互延迟。通信开销、同步开销和调度复杂度很快会成为新的瓶颈。它是必要的基础设施,但很难成为video model效率问题的根本答案。
所以如果只问“加速video model最实用的方法是什么”,我的排序大概是:蒸馏、并行、量化,对于个人玩家,还有cache。稀疏和剪枝当然有价值,但很多还处在科研验证或者特定场景toy model的阶段。真正能进入工业链路的,一定要证明自己不只是省FLOPs,而是稳定省延迟、显存和成本。
长视频不是世界模型
综述还讨论了自回归、AR-Diffusion混合、因果流式生成、memory mechanism等方法。这些方法的目标不是只生成一个短clip,而是让模型能够持续续写、接收动作、保持上下文,从而更接近world model。
AR能够在语言模型中如鱼得水,我认为有赖于语言本身是人类发明的高度压缩的一维符号系统,容易分割,意义明确;但是对于图像甚至视频,再好的encoder也很难用有限token完整而准确地表达其内蕴的信息,此外视觉存在高度的空间置换不变性和组合性,而一维AR的自回归因果掩码却破坏了这种空间双向交互。因此视觉生成只能更依赖full attention的全局视野、密集计算,以及一次又一次的迭代去噪修正。
AR+Diffusion的混合方案很自然:AR负责时间延展,Diffusion负责每个chunk内部的画面质量。因果流式生成则试图把Diffusion本身改造成streaming rollout,通过causal attention、block-causal设计和forcing类训练方法,让模型不依赖未来帧也能继续生成。
我认为混合架构和流式生成考虑了时间和空间维度的不同性质,这种解耦的架构更加优美,也更有机会成为世界模型。遗憾的是,当前效果仍然不够好:分钟级生成里仍然会出现结构坍缩、物体漂移、背景幻觉、人体变形等问题。它们说明模型能生成更长的视频,不说明模型真的维护了一个稳定世界。
最接近真正world model的也许是spatial memory。一个世界不应该只是过去帧的集合,而应该有某种可查询、可更新、可保持的状态表示。Visual memory保存关键帧,compressed context压缩历史,implicit memory把上下文写进模型状态;但如果要维持3D一致性和物体持久性,显式或半显式的空间记忆可能还是绕不过去。
纯视频模型缺的恰恰是这个东西:它生成的是观测,不是世界本身。把观测当世界,会导致模型只要画面看起来连续就算成功,但这和“知道物体在哪里、状态是什么、受力如何变化”不是一回事。
应用
综述最后讨论了三个应用场景:自动驾驶、具身智能、游戏/交互式世界模拟。
自动驾驶是最容易讲故事的场景。真实道路数据昂贵,长尾危险场景稀缺,传统仿真又难以做到足够真实。视频世界模型看起来正好可以生成可控的驾驶视频,用于数据合成、闭环仿真和规划评估。GAIA、DriveDreamer、Vista、Drive-WM等工作都在这个方向上推进。
但这里有一个关键问题:自动驾驶需要的不是“像真的视频”,而是“可验证的世界”。如果模型生成的车辆轨迹、遮挡关系、交通规则只是视觉上合理,却没有严格的物理和语义约束,那么它作为训练数据还勉强可以,作为规划环境就很危险。世界模型一旦参与决策闭环,幻觉就不再只是画面瑕疵,而是系统性风险。
具身智能也是类似逻辑。视频模型可以作为data engine,生成更多机器人操作视频,也可以作为虚拟环境,让策略在里面试错。这个方向很诱人,因为真实机器人采数据太慢、太贵、太不稳定。但机器人控制比视频生成更残酷:一个动作是否成功,取决于接触、摩擦、力反馈、物体材质和执行误差。单纯从视频中学到的“物理常识”,很可能只是视觉相关性。
游戏和交互式世界模拟反而是更现实的落点。游戏世界的规则更封闭,动作空间更清楚,评价也更直接。生成式模型只要能做到实时、连贯、可控,就已经有价值。GameGen、MineWorld、Matrix-Game这类工作,至少把问题放在了一个边界更清楚的环境里。
总结
这篇综述读下来,我的感觉是:它名义上在讲Video Generation Models as World Models,但主要内容仍然是在讲video model,以及如何让video model更快。
从video到world model,当前最显眼的瓶颈确实是效率。扩散太慢,full attention太贵,长视频太吃显存,实时交互基本不现实。所以综述把大量篇幅放在蒸馏、cache、并行、attention优化、量化上,这是合理的。
但效率只是直接矛盾,不是根本矛盾。哪怕我们把视频模型加速到实时,它也不自动变成世界模型。因为世界模型需要的是稳定的状态表示、可组合的因果结构、长期一致的物理约束,以及动作和后果之间可依赖的映射。现在的视频模型更多是在学习观测分布,而不是学习世界本身。
这也是我对当前“世界模型”叙事比较谨慎的原因。它很有想象力,也确实可能成为AIGC走向Agent形态的一条路,但算法还不成熟。很多工作是在把video generation往world simulation上解释,而不是已经解决了world modeling的问题。
所以这篇综述适合读一读,了解一下领域里大家把video model用到了哪些场景,以及视频模型加速有哪些主流技术路线。至于“视频生成模型能不能成为世界模型基座”,我的答案是:可能可以,但不是现在这套算法自然scale up就能解决的事情。
现阶段,VGM到WM之间还差一个更本质的东西。不是更快的采样器,也不是更长的context,而是对世界状态和因果机制的可控建模。