调研:稀疏注意力
注意力稀疏,头发就不稀疏。
无论是LLM还是DiT,面对长序列计算attention的计算和内存瓶颈,稀疏化几乎是最promising的方案。 所以我们今天来学习最新的稀疏化技术。
- Preliminary:MHA、MQA、GQA和MLA
- NSA:Hardware-Aligned and Natively Trainable Sparse Attention
- FSA: An Alternative Efficient Implementation of Native Sparse Attention Kernel
- MoBA: Mixture of Block Attention for Long-Context LLMs
- FlashMoBA
- DSA:DeepSeek Sparse Attention
- DSV:Dynamic Sparsity for Video DiT Training
- SVG:Spatial-Temporal Sparse Attention for Video Inference
- VSA:Trainable Video Sparse Attention
- SLA:Sparse Linear Attention
- Sparge Attn: Accurate and Training-free Sparse Attention Accelerating Any Model Inference
- 总结
Preliminary:MHA、MQA、GQA和MLA
主要参考:苏剑林:缓存与效果的极限拉扯:从MHA、MQA、GQA到MLA
MHA:最传统的多头注意力,定性而言,每一个头代表了一种关注的特征(QKV的表示空间)。从这里也引入了decode阶段的KV Cache,相应地,每一个head都有自己的KV。
MQA:2019年在Fast Transformer Decoding中被提出,看来天下苦KV Cache久矣。简单而言,多头Query共享一个KV。好处是Attention的参数量减少了将近一半(KV的Linear),坏处是精度的下降和FFN中参数量的相应提升。
GQA:一个折中方案,一组Query共享一个KV。在Llama2/3中被使用,组大小为8。有趣的是,这个参数设置是软硬件codesign的结果。在LLM必须分布式部署的时候,g=8恰恰是最满足张量并行效率的组大小。
MLA:在DeepSeek-v2中被使用,从投影的角度压缩了KV,带来了更灵活的显存精度调整,同时通过低秩进一步压缩KV Cache。同时,在压缩的$c_t$序列上,增加部分序列来添加RoPE位置编码。
稀疏 Attention(Sparse Attention) 的定义非常直观:在计算注意力权重时,不再让每个 Token 都与序列中所有的 Token 进行交互,而是根据某种规则,只选择一小部分“重要”的 Token 进行计算。 实现稀疏化的最大挑战在于:我们如何预知哪些 Token 之间是重要的? 理想情况下,我们希望只计算那些注意力权重大的点位。但尴尬的是,在不进行全量计算之前,我们很难精确知道哪些位置的权重会大。为了解决这个“先有鸡还是先有蛋”的问题,目前有三种主流方案:
- 先验固定模式 (Fixed/Static Patterns):基于对语言特性的观察(如局部相关性),人为设定一套固定的计算规则,不随输入内容改变。
- 在线动态预测 (Online/Dynamic Prediction):在推理过程中,利用轻量级的算法实时预测哪些 Token 是“潜力股”,从而只对它们进行精确计算。
- 后训练 (Post-training/Learned Sparsity):在模型训练完成(或微调阶段)后,通过进一步训练分析模型已有的注意力分布规律来确定稀疏模式。
| 方案类型 | 开发工作量 | 理论效果 | 硬件友好度 | 适用场景 |
|---|---|---|---|---|
| 先验固定 | 低 | 中 | 高 | 预训练长文本模型、端侧轻量化 |
| 在线预测 | 中 | 中上 | 中 | 动态长度变化大的序列处理 |
| 训练后预测 | 高 | 极高 | 中下 | 大模型推理加速、KV Cache 压缩 |
在我看来,一个好的稀疏策略,一定是既要又要还要的: 既要前置工作简单,又要算法一致性高,还要硬件友好。
NSA:Hardware-Aligned and Natively Trainable Sparse Attention
25年2月,北大DeepSeek https://arxiv.org/abs/2502.11089。
这是ACL25的best paper,有趣的是DeepSeek v3.2并没有采用这个架构。
NSA overview
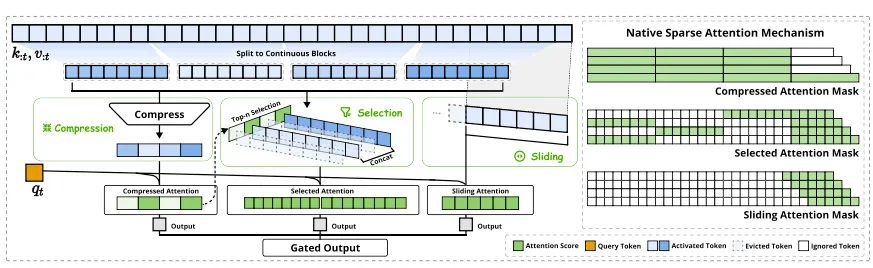
对于每一个输入的query,NSA首先对完整的KV序列进行token compression,通过一个粗粒度的compressed attention进行稀疏选取,再做细粒度的稀疏attention运算。对于靠近当前Query token的context,则做sliding window attention,也就是无需压缩,默认被选择。
这种选择性注意力的方案首先当然能显著减少计算开销,更好的是,能够提升注意力的性能(本质上是减少无关噪声,从而“集中注意力”)。
现有稀疏的局限
很多方法虽然声称降低了计算复杂度,但实际推理延迟并没有相应减少。主要源于两个限制:
- 阶段限制:有些方法只能在prefill或decode阶段实现稀疏,导致在特定任务场景下无法获得理想加速。
- 不兼容现代注意力架构(如MQA、GQA):虽然减少了计算量,但内存访问模式与这些架构的高效设计相冲突
训练时稀疏遭遇困难:
-
Post training的稀疏化会导致模型偏离预训练的优化轨迹,造成性能下降。
- 现有的稀疏方法往往是推理时应用,无法解决训练的稀疏挑战。
- 因为稀疏的离散操作阻断了梯度传播,内存访问的不连续导致无法利用高效注意力算子
算子设计
算子要求是:支持训练、支持prefill和decode、支持GQA和MQA,还要达到Flash Attention的性能。
因此必须将稀疏和硬件对齐,算子在Triton层面进行设计。又因为compression和sliding window本身就是full和causal且连续的计算操作,因此只需要设计sparse selection attention。
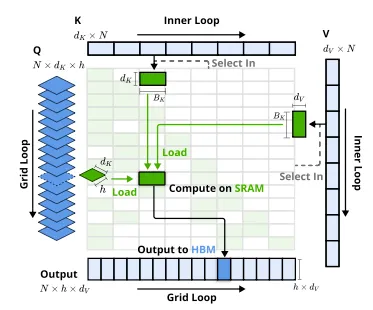
说白了就是加载固定blocksize的indexed KV去尽量填充SRAM和Tensor Core,outer loop逐个过Q生成output,inner loop则将indexed KV过一遍。
FSA: An Alternative Efficient Implementation of Native Sparse Attention Kernel
25年8月,Relaxed System Lab,https://arxiv.org/pdf/2508.18224
港科大和CMU,提出了NSA的Sparse Selective Attn的另一种实现—Flash Sparse Attention。
Motivation:NSA的问题
高效的稀疏,意味着将理论上sparse减少的Flops转换为实实在在的访存和计算的减小。
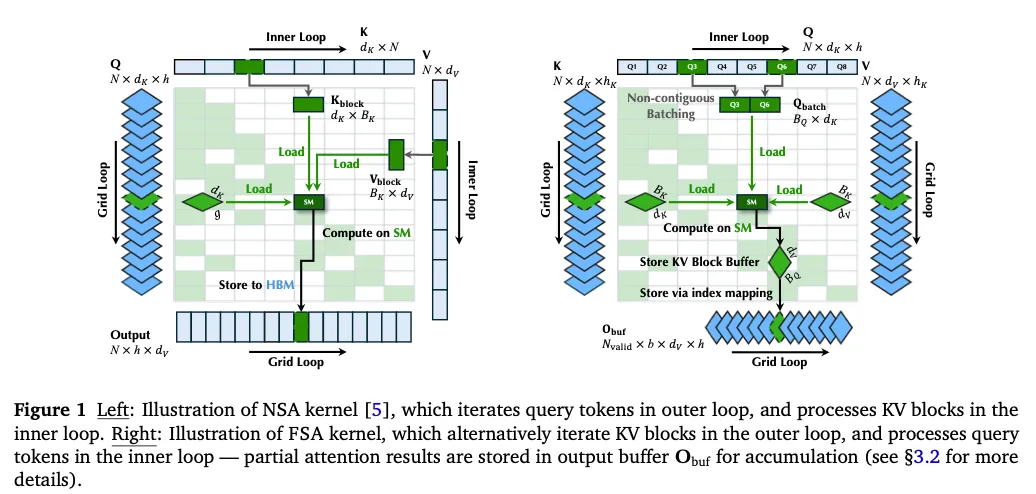
NSA:batch处理Query head,但如果Query head数量不够,就需要padding来满足tensor core的矩阵乘形状限制。如图2所示,在head不够的时候,padding操作会带来超级多的padding访存和计算浪费。
FSA换了一下,在inner loop去遍历Q,而KV则在outer loop。因为decode阶段中KV的数量足够多,因此可以保证KV head的运算是满的。
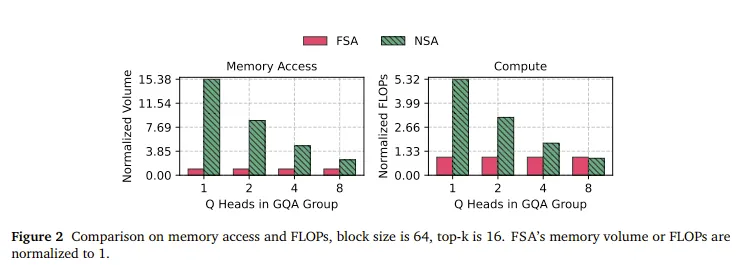
挑战和方法:FSA难在哪
-
访存不连续:对Query token的访问与KV index直接相关,不连续访存的开销很大。
方法:使用index tensor去调控数据的搬移,使用两类索引张量:输入索引Ii和输出索引Oi。其中,Ii记录了每个KV块需要处理的query token的索引,Oi则用于管理中间结果的连续存储,他们都是NSA预先计算得到的。理论上说,NSA的定Q访存KV和FSA的定KV访存Q,再做online softmax,所需要的访存量是相同的。
-
一个Query的online softmax结果分散在不同KV 对应的thread block当中。如上图NSA中,需要开辟一个buffer进行结果的累积。
方法:分离设计了一个专用的reduction kernel在buffer中进行online softmax结果的reduce。分离kernel会带来额外开销,但如图2右边所示,并不高。
Evaluation解读
尝试解读一下实验结果,直观观察一下NSA和FSA的优势和insight。
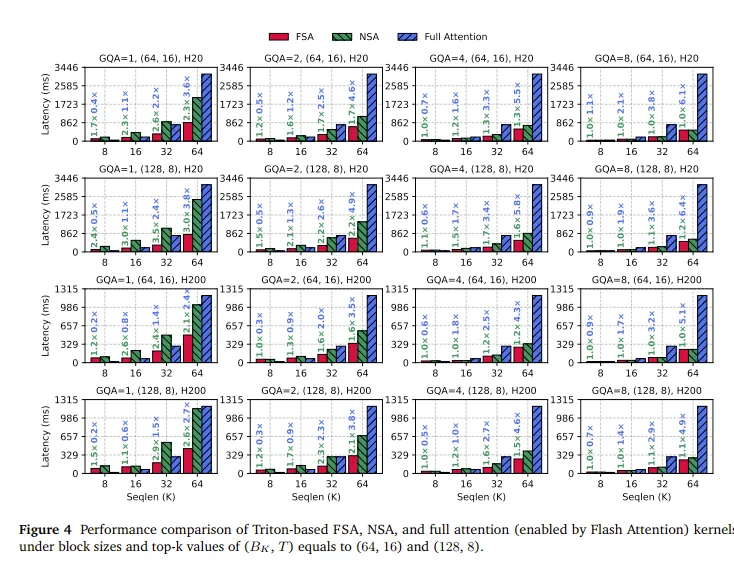
- X轴:序列越长,各种Attention计算的Latency都在增加,但Full Attention是二次的,Sparse Attention由于topk的KV,是线性的,因此序列越长,SA的优势就越明显。
- Seq=8K,full Attention反而是最快的。因为sparse也要选择$64\times16=8192$个KV,计算量没有减少,白白多算一次。
- Seq=16K,GQA=1(第一列)。FSA在(64,16)时比Full快,在(128,8)时比Full慢,这个不太确定,感觉与压缩效率有关。NSA则都要更慢,因为Query的group太少了。
- GQA=4的时候(第三列),NSA慢慢也能稳定优于Full了,但仍然弱于FSA,GQA=8(第四列,经典配置)时,性能基本持平,NSA没有了padding开销,那么FSA理论上限也就和NSA一致。
MoBA: Mixture of Block Attention for Long-Context LLMs
25年2月18日,与NSA同日发布的Kimi工作。https://arxiv.org/abs/2502.13189。不得不说Kimi还真是跟DeepSeek杠上了,内部是不是有什么通气或者间谍之类的哈哈哈,这两个工作有点太像了。不过有竞争总是好的。
Motivation都是一样的,多快好省地扩展上下文长度。MOBA认为现在主流方案就是线性注意力和稀疏注意力,或多或少加入了启发式的偏见,一个典型就是sliding window attention和线性注意力。MOBA则应用MoE的原理,将怎样使用注意力交给模型的梯度下降来决定:以一种更加“客观”的方式实现稀疏注意力,理论上会更加接近最优。
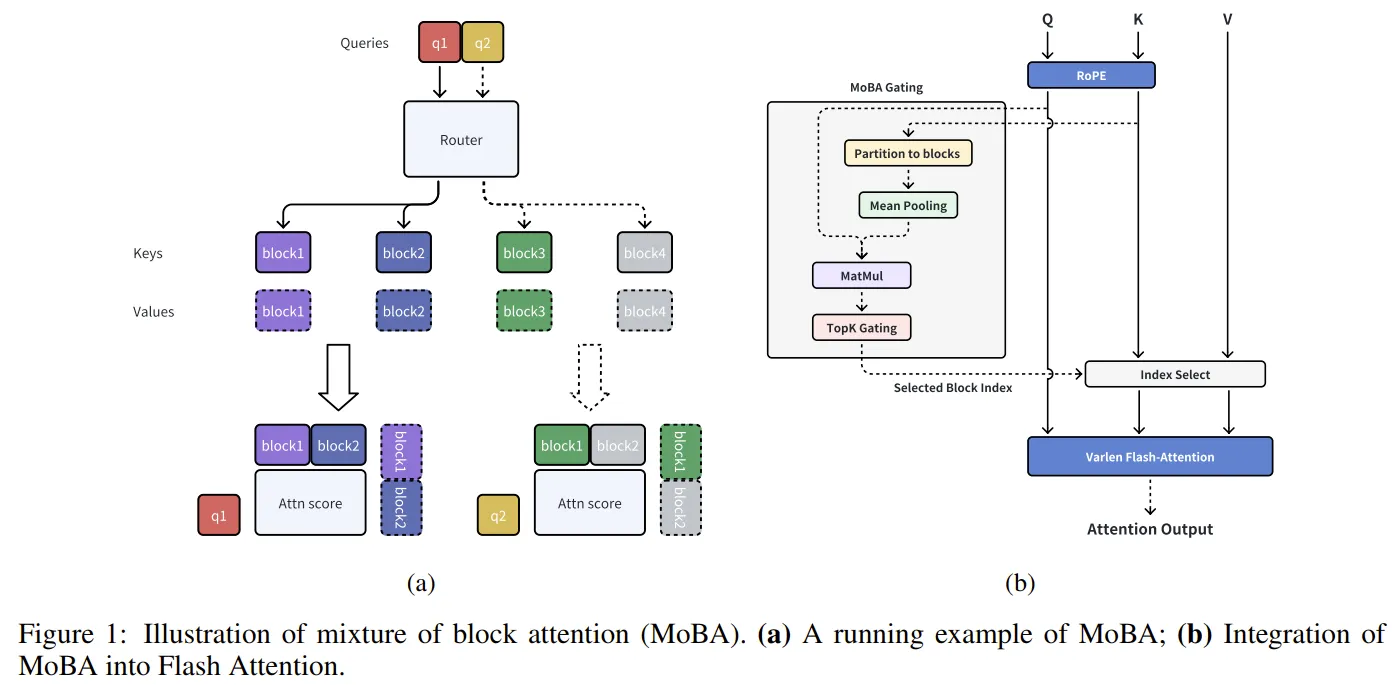
仍然是选择KV的核心思想,将KV按照block来分组。每个Q去路由到自己喜欢的KV那里。至于选择,将K按照block压缩,然后通过Q和Compressed_K的矩阵乘运算结果来选择topK。
妈呀,除了没有local的sliding window这个先验的设置以外,其他和NSA实在是太像了。因此我们转向两种架构的异同对比,这里参考了知乎文章:大模型注意力机制革新之战:NSA与MoBA架构深度解析,不过有点像大模型生成的,不知道用的DeepSeek还是Kimi哈哈哈。
我并不认为NSA中的compressed indexer和MoBA中的block router有什么本质区别,从结果和开销上都是相似的。NSA用了triton重写,MoBA则是较高级的python代码,但这也不是本质区别,最重要是算法要好,算子的优化都可以由后人来做。
FlashMoBA
既然有FlashNSA,自然也有FlashMoBA。25年11月,MiT和Nvidia就跟进了对MoBA的算子支持(从支持的组织水准上,看似MoBA的业界反响更好,但也可以认为DeepSeek已经自己将这一步完成了,FSA相比于NSA更像是平替而非上位优化)https://arxiv.org/pdf/2511.11571
Motivation是:
- MoBA的简化结构设计理念使得其可理解性不强
- MoBA缺乏高效的算子支持
所以需要做codesign,完成高精度、硬件友好的参数选择。
算法建模
从精度上,论文中给出了基于对MoBA做数学建模的结论。这个建模也并不复杂,就是将实际topk作为groundtruth,尽可能提高router的准确率,然后量化分析与之相关的超参数即可,最后得出来两个比较启发式的结论:
- 优化head dimension和block size的比值,这直接关系到router选择的信噪比
- 对key做一个卷积,更好地收集信号。
算子优化
MoBA在blocksize不够大的时候,同样遇上了访存密集的问题,此时top-k和gating反而成为了瓶颈。
从硬件优化上,韩松组还是用上了他们的“一招鲜吃遍天”——稀疏重排后稠密计算。
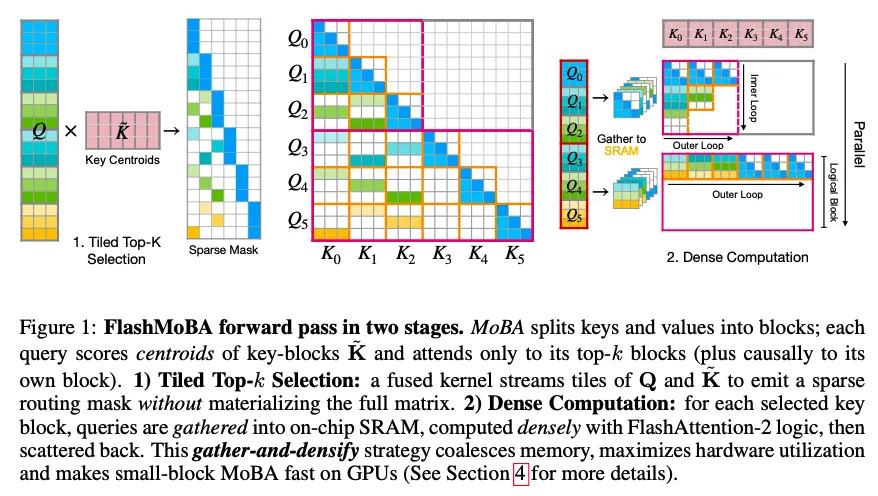
这个图画得很好看很清晰,识别出了selective mask中的两种数据模式并进行了简单而高效的重排,他们将这个过程写成了三个高效的算子。
实验结果
精度结果验证了他们关于headdim和blocksize对信噪比影响,将blocksize变小,提高选择的粒度会好一点。让我们着重关注效率结果:
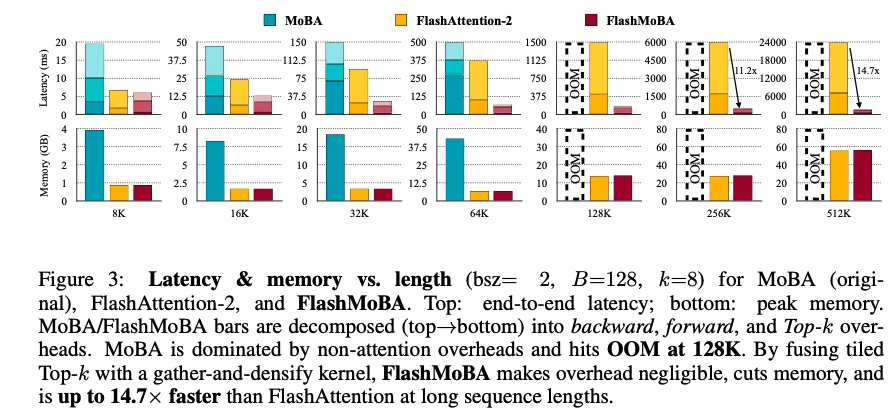
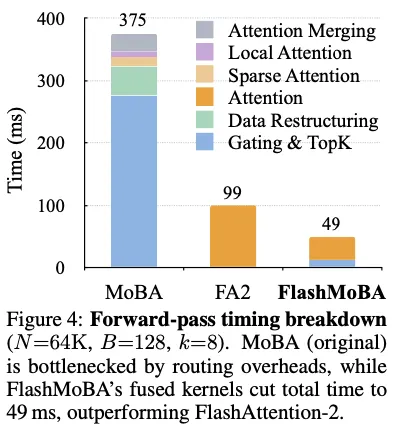
最奇怪的是,MoBA在所有情况下都被Flash Attention打烂了,其中的topk和gate在速度和内存开销上都无比差,其中breakdown如下图所示,这个结果和MoBA论文中的结果不太一致,如果是这样的效果,Kimi发MoBA岂不是招笑。是什么原因造成的?论文中貌似没有明确给出说明。
仔细对比发现,MoBA Origin中Blocksize设置为512,TopK=3,而此处Blocksize=128,TopK=8 ,也就是人为地细化了Blocksize。妙就妙在,他们的精度建模支持了这个参数的效果要更好。看到这里,不禁感叹,codesign好啊,codesign得学,不过先有靶还是先有箭,只有作者自己清楚。
DSA:DeepSeek Sparse Attention
在DeepSeek v3.2中用到的Attention架构。https://github.com/deepseek-ai/DeepSeek-V3.2-Exp/blob/main/DeepSeek_V3_2.pdf起这个名字,说明DeepSeek对这个架构的无比自信。在其充分被传唱之前,我会将DSA理解为Double Sparse Attention,就像显微镜一样,凡是精度足够高的设备,都会分为粗准焦螺旋和细准焦螺旋进行二级调控。
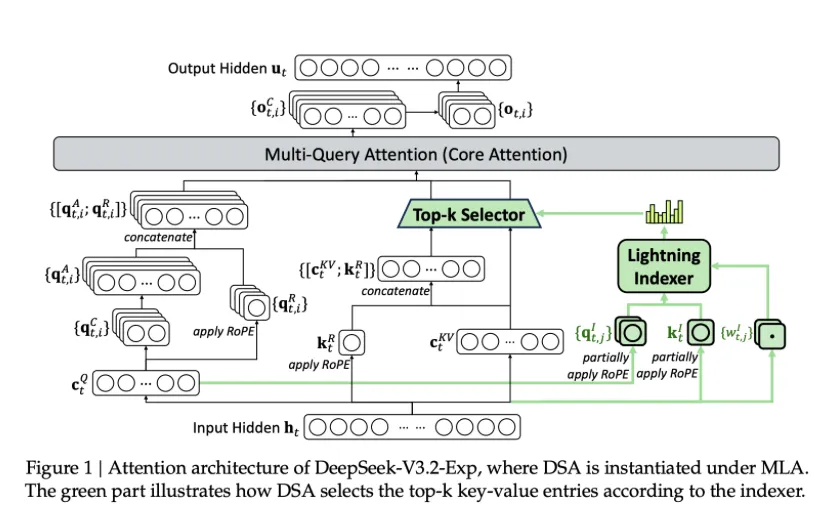
DSA沿用了NSA的选择KV的思路,同时结合了V2中MLA压缩KV表示的思想。绿色部分就是在v3.1的MLA基础上新增的sparse attention的内容。此时,k仍然会被计算,用于在lightning indexer(应该就是NSA中小的blockwise attention)中对c进行topk的选择。
后训练
V3.2是在V3.1的MLA基础上续训的,分为两个阶段:
- Dense Warm-up Stage:冻结其他参数,让lightning indexer能够学习到dense attention中KV的选择策略。
- Sparse Training Stage:打通indexer的pipeline以后,全局参数的微调。
听上去很合理,新增的先适应旧的,全局再做微调。
结果
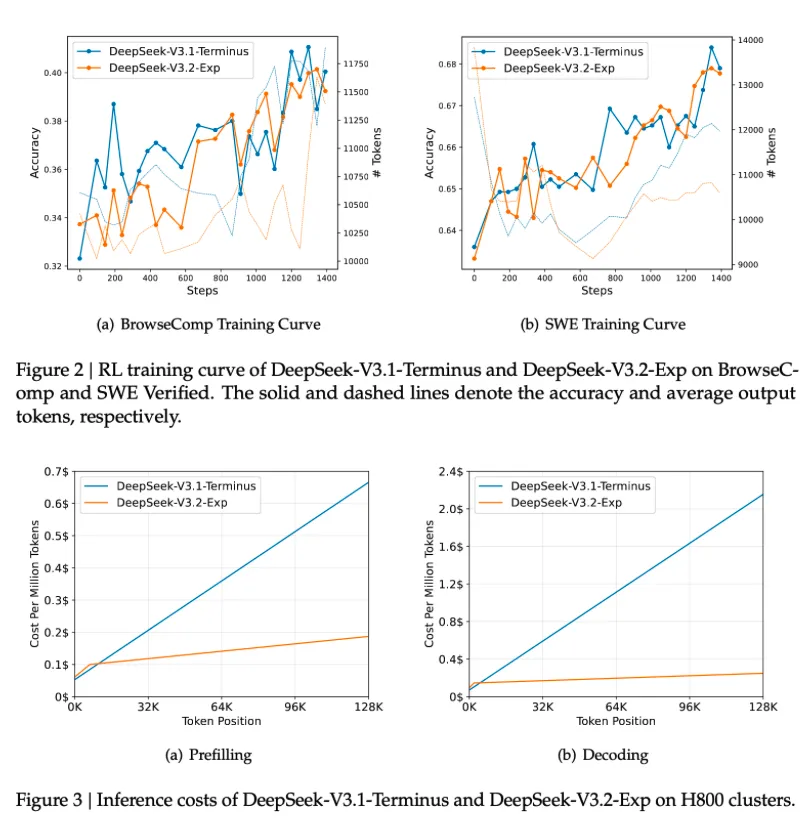
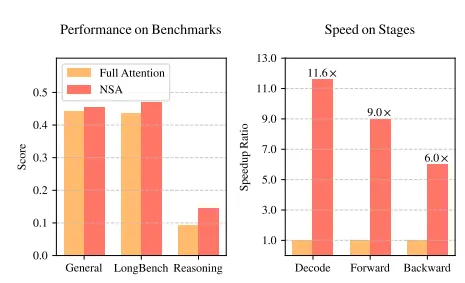
上图直接说明了,一致的训练精度收敛曲线下,DSA能够大幅度减少每个token的生成成本,随着seqlen增长,sparse的意义越发明显。
DSV:Dynamic Sparsity for Video DiT Training
25年2月,港中文和StepFun的文章,在训练中应用了稀疏注意力,也许这是StepVideo的训练方案?不过StepVideo大是大,效果并不算很好,而在推理过程中,用到的仍然是Full Attention,慢也是够慢。
观察
他们的核心观察是:在video DiT中,稀疏度很高,而sparse pattern不是固定的。
算法设计
因此DSV使用了两阶段的训练过程,第一阶段训练低秩近似的预测器来估算注意力分数,从而捕捉关键KV。第二阶段利用关键KV训练全局参数。然后,DSV设计了专用的predictor和sparse Attn算子。最后,DSV还支持了序列并行的sparse训练,在128卡的集群上完成了训练。奇怪的是,没有相关的原生支持sparse的开源模型发布,有点美中不足。
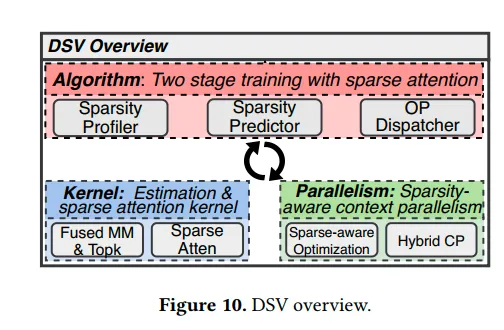
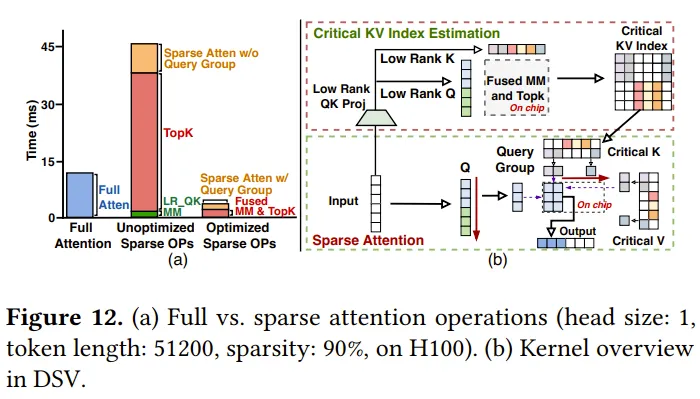
算子设计
下面这个图就说明了这个问题,低秩的attention本身开销不大,但是topK是一个memory bound的效率极低的排序操作,而Sparse Attention本身也还有硬件适配的优化空间。
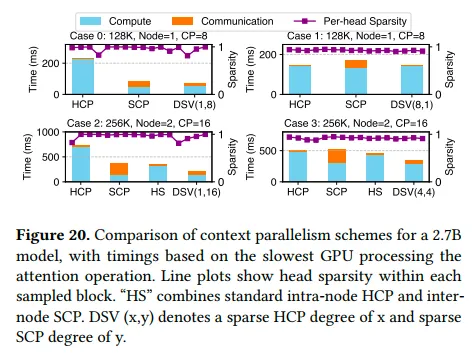
并行设计
DSV则在selective KV的基础上,实现了headwise-CP和sequence-wise CP(其实就是Ulysses和Ring-Attention)。二者的结合策略主要受限于head数量以及通信的开销和计算通信重叠的实现,Head-wise CP应该通信量和计算量会更加均衡一些,对于跨节点的情况,则优先使用sequence-wise CP做点对点通信,在sparse pattern已知且不均衡的情况下,应该可以有进一步的通信优化。DSV也是按照这个顺序进行实现的:
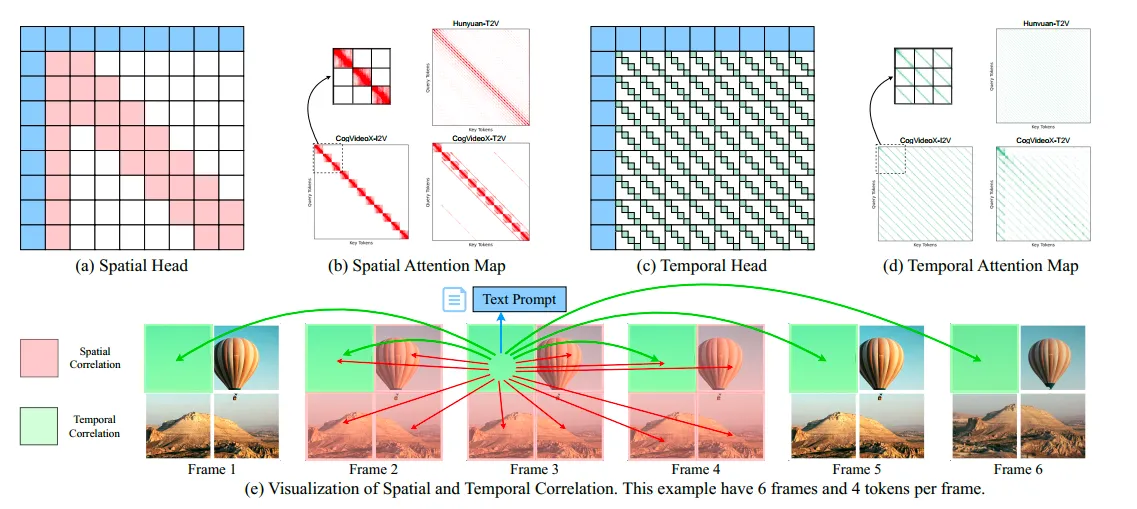
SVG:Spatial-Temporal Sparse Attention for Video Inference
25年4月,MiT Han-Lab的工作,ICML25 ,也许这是第一篇在视频生成中做稀疏推理的文章。https://arxiv.org/abs/2502.01776 。
SVG中的稀疏策略比较简单,其sparse pattern是固定的,因为他们觉得视频生成DiT中的head可以被二分为spatial head和temporal head。并基于此pattern设计了特定的layout transform和稀疏kernel。此后还有SVG2,仍然使用train-free设计,不过承认了稀疏pattern并没有那么固定,采用了更灵活的预测方法。
VSA:Trainable Video Sparse Attention
25年10月,UCSD Hao-lab 的工作。https://arxiv.org/pdf/2505.13389
必要性
通过在训练过程中引入稀疏来实现关键token的选择,DiT推理当中Full Attention是真正的计算大户,而且Video的attention局部性要更加明显,因此DiT generation相比LLM Decode更加需要稀疏化和高效化。随着NSA和MoBA的出现,这种稀疏架构被应用于DiT几乎是必然,比拼的就是发文速度。不过这一篇文章,确实做得很solid,实验完整,也提供了新颖的观察。
难点和方法
训练时稀疏的难点,算法上在于如何准确而先验地寻找关键token,硬件上在于稀疏化以后如何适配Flash Attention算子。
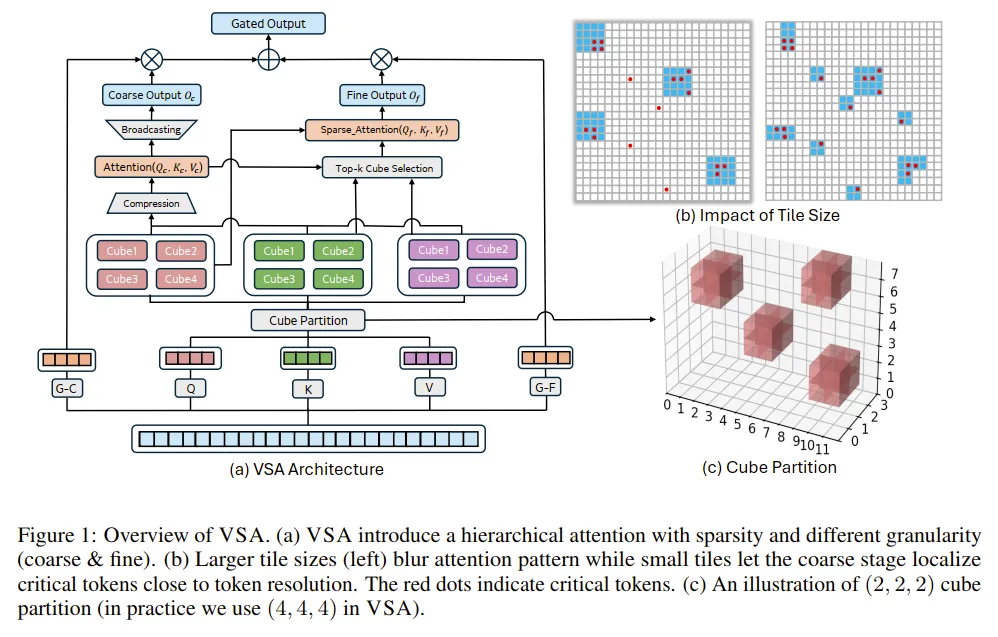
方法也是同样的:压缩QKV做粗粒度attention进行topK搜索,细粒度分cube KV做稀疏attention。其中,cube size的选择会带来精度和算子效率的tradeoff。与MoBA不同的是,VSA通过gate合并了粗粒度和细粒度输出,作为一个压缩后全局信息的补充。然后就是:
“我想要说的前人们都说过了,我想要做的卷王们都做↓过↓了↑!”
实验
精度优势: 加速video的工作有很多,大部分是质量换速度,以TeaCache为代表Feature Reuse系列工作以实现简单,效果明显的特点,不知养活了多少研究者。Sparse Attention作为门槛更高的技术,其优势就应该体现在稀疏以后,能够保持甚至提高生成的质量,最不济也应该推进latency-quality的tradeoff边界。从实验上看,VSA能够做到这一点:
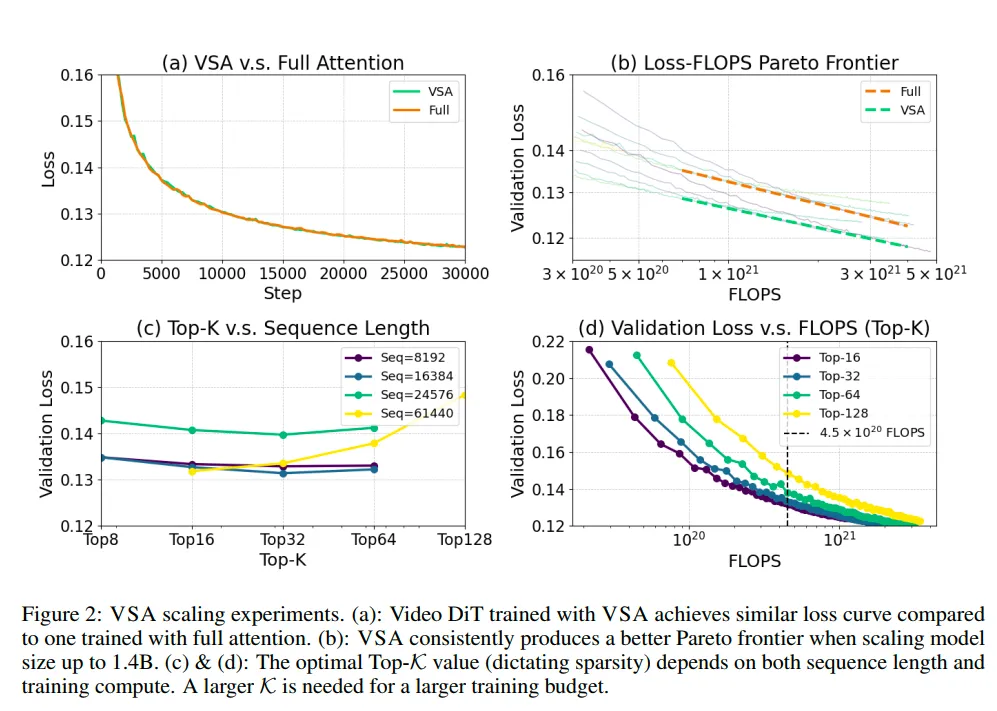
在训练精度上的ablation study,反应了VSA中参数选择的逻辑,也证明了稀疏attention的作为更高阶有损加速方案的好处。
动态策略:
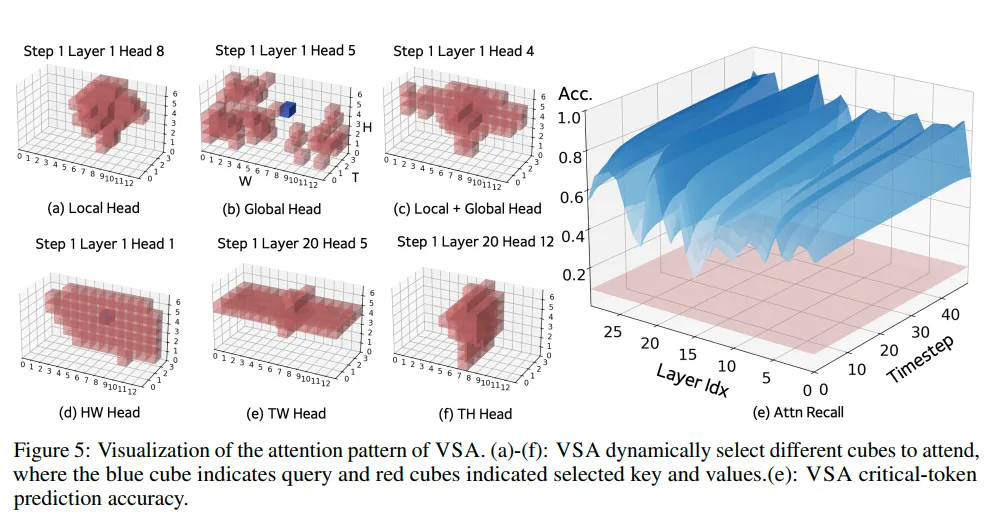
文章认为,将稀疏模式固定的工作注定是次优的,他们提供了在Wan1.3B上的稀疏模式可视化,体现出了attention head的稀疏性会随着生成的内容高度变化,这几乎直接cue的是Song Han的Sparse Video Gen文章,与他们的观察针锋相对。上面的实验并不足以支撑他们“内容相关”的结论,应该给出不同prompt下的同head图案统计分布。
与DSV对比
VSA和DSV在稀疏训练上的思想比较接近,VSA认为DSV的主要缺点在于其系统复杂,专门设计了low-rank predictor,还做两阶段的分离训练。也许要怪DSV没有开源,VSA没法和它直接定量比较,只能强行骂一下,谁优谁劣还真说不定。只能说从设计和实现的完整度以及工作量来看,DSV是要更高的。
=============== 新的一年,补充一些工作 ^ v ^============
SLA:Sparse Linear Attention
25年11月,THU 朱军组很新的工作,目前还在arxiv状态。
Abstract
- 领域:集中优化DiT attention。我猜测的原因是,语言模型中的casual attention矩阵一般无法低秩。
- Key Observation:Attention weights can be decoupled into two matrices: a small fraction of large weights with high rank and the remaining weights with very low rank. 注意力矩阵分解:高秩小权重+低秩大权重
- Core Idea:高秩部分用稀疏,低秩部分用线性。
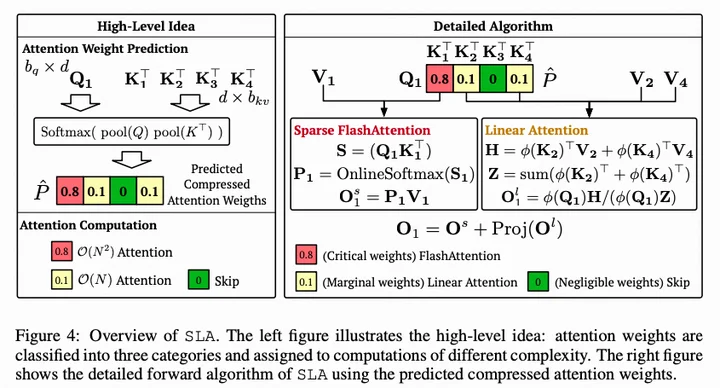
- Method:需要微调(trainable)以区分关键权重、边缘权重和可忽略权重。关键权重完整算,边缘权重线性算,可忽略权重不算。并fuse成一个kernel。
一个写作小技巧:不用训练是优点(train-free),要训练也是优点(trainable),你学会了吗?
- Contribution:几步微调,将注意力计算降低95%,attention延时提升13.7x,端到端2.2x。
如何理解“秩”
- 高秩部分(High-rank): 极少数权重极大的点位。它们代表了精确的物体结构、运动边界等关键特征。这部分信息是“不可压缩”的,构成了矩阵的主要秩。
- 低秩部分(Low-rank): 剩余的大量微小权重。它们通常代表背景、全局光影等平滑的上下文。这部分信息具有极高的冗余度,可以用低秩矩阵完美近似。
这种方案在文本上可能提升有限,但在视频 DiT 中却很有效,因为:
- 时空冗余性(Spatiotemporal Redundancy): 视频中相邻帧的背景几乎不变。这意味着在注意力矩阵中,存在大量的低秩背景信息,线性注意力处理这部分信息的性价比极高。
- 特征稀疏性: 视频生成的关注点通常集中在少数运动主体上。相比静态图像,视频的注意力分布更加“稀疏且尖锐”,这为高秩/低秩的解耦提供了物理基础。
方法
与Sparge attention大致相似,只是预测除了稀疏的“要算”和“不用算”以外,还多了一个“辩证地算”(线性)。
实验:与Sparge的比较
实验中SLA的数据很漂亮,几步微调,将注意力计算降低95%,attention延时提升13.7x,端到端2.2x。
但我注意到一点,SLA用了Sparge Attention作为baseline,效果很差:
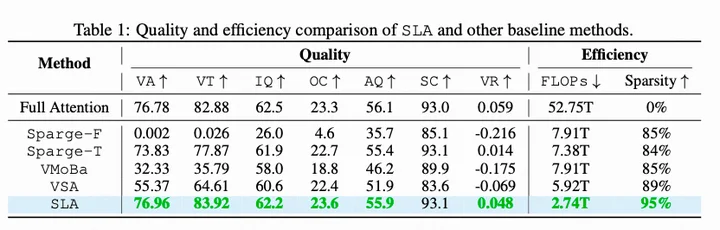
奇妙的是,一个trainable的sparge attention出现了,而且效果比同样训练的VSA还好。
我理解SLA比VSA好在linear的添加,那么sparge-T比VSA就好在sage的添加。
但标准Sparge在Wan2.1-1.3B上的失败让我无法理解,于是我去问了作者Jintao,他说:
SpargeAttn的标准api在Wan2.1-14B上效果其实是很好的,但在1.3B上,效果确实不太好,这可能跟模型经过蒸馏稀疏度降低有点关系。 SpargeAttn-T是增加了backward的可训练sparge attn版本,效果确实比VSA更好,也许是因为算法上更加合理,未来将会开源。
在我看来,SLA中的低秩性观察是比较启发式的,并没有那么promising,而需要微调这一点也会劝退比较多的用户。作为一般的推理用户,我为视频模型选择合适的注意力算子,会倾向于选择下面一篇:Sparge Attention。
Sparge Attn: Accurate and Training-free Sparse Attention Accelerating Any Model Inference
sparse可以和linear结合,也可以和量化(sage)结合!
ICML2025,同样THU 朱军老师组的工作。Sparge是Sparse+Sage attention,在sage量化的基础上利用attention的稀疏性提供更好的性能。比SLA早一点,但是是更通用和完善的工作,因此放在压轴写。
文章的目标是:”A universal sparse attention that guarantees both the speedup and end-to-end performance of diverse models “
这里的universal、speedup、end-to-end performance都很难,而universal就更难了,因为attention patterns高度异构。
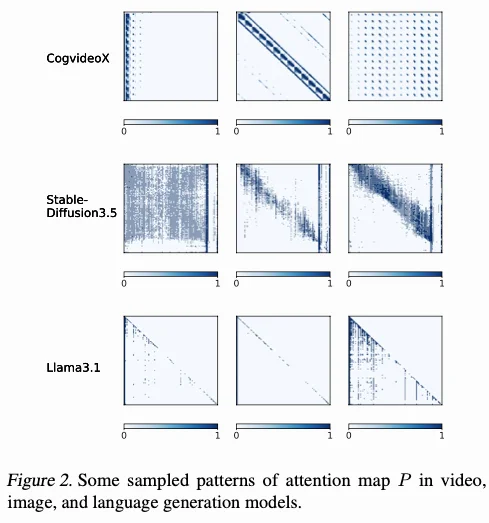
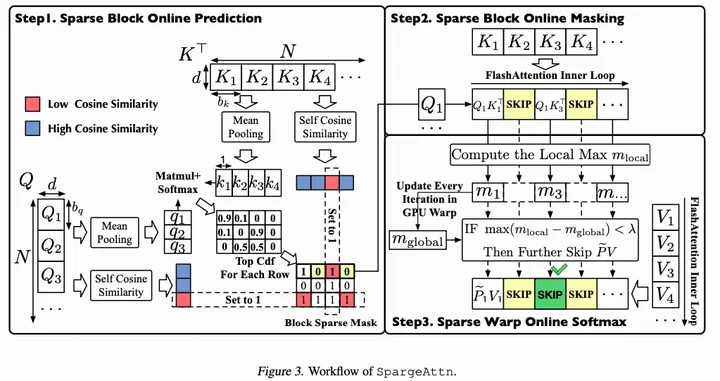
预测算法
Sparge Attention提供了一种通用的算法:选择性压缩QK来构建稀疏mask。从Q和K中先通过cos similarity将token划分为相似的block,再用Mean Pooling将block压缩为compressed token进行sparse pattern计算 (matmul+softmax)。
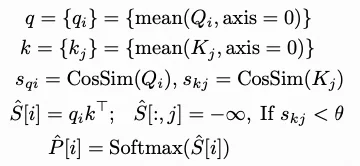
(我认为这个预测算法是Sparge Attn的精髓,后面的都是工程实现与正交优化。)
除此以外,还有GPU warp 级别的稀疏online softmax算法 ,这个其实挺直观的。
算子实现
将稀疏方法集成到8-bit量化 Sage-Attention framework :Sage attention 是对QK做量化但不跳过计算,Sparse策略则判断是否跳过计算。说是正交,其实对性能的影响是叠加的。但是二者的结合实现起来比较简单。
小巧思

说明sequence本身就具备较好的locality,这种方式在稀疏中也比较常见。但2维转1维的方案还是效果有限,从后面的实验部分可以看出来。
实验
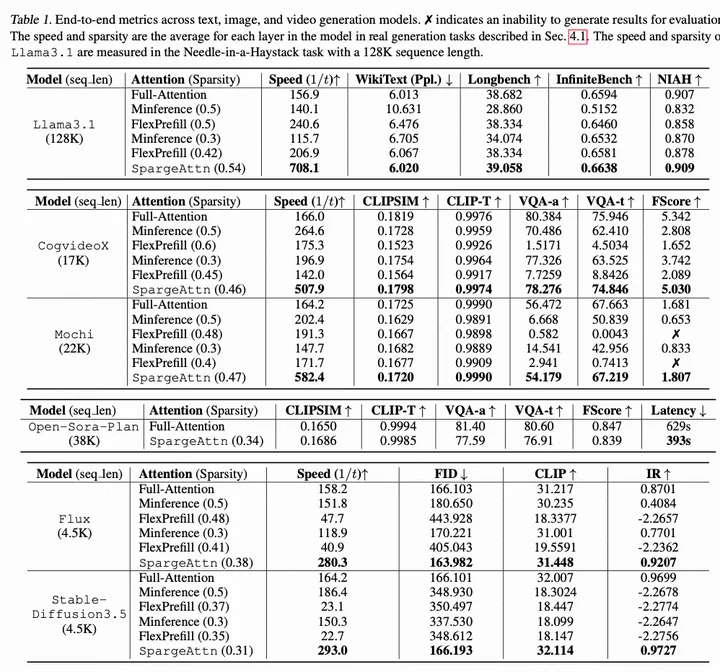
Sparge attention的实验做得比较完善。而且在llm和dit中都有比较好的表现。而且train-free,确实值得试用。
总结
稀疏和线性注意力已经成为了“后注意力时代”的宠儿,LLM和DiT社区都在拥抱这样的架构。先用粗视野“挑选”,再用细粒度“观察”也符合人脑做注意力的趋势。
从系统角度,LLM上应用稀疏能够加快Decode速度,但仍然收到KV Cache的显存限制。DiT应用稀疏则有极其直接的优势。而稀疏性直接与软硬件codesign绑定,算法设计、算子设计和并行设计逐渐变得耦合,也许是未来软硬件不分家的曙光初现。